Lecture 10: High performance computing – Lecture
January 18, 2024
3.1 Top500
- List of the most powerfull supercomputers in the world: Top 500
- Released every half-year, now November 2023 release
- Not all computers are listed
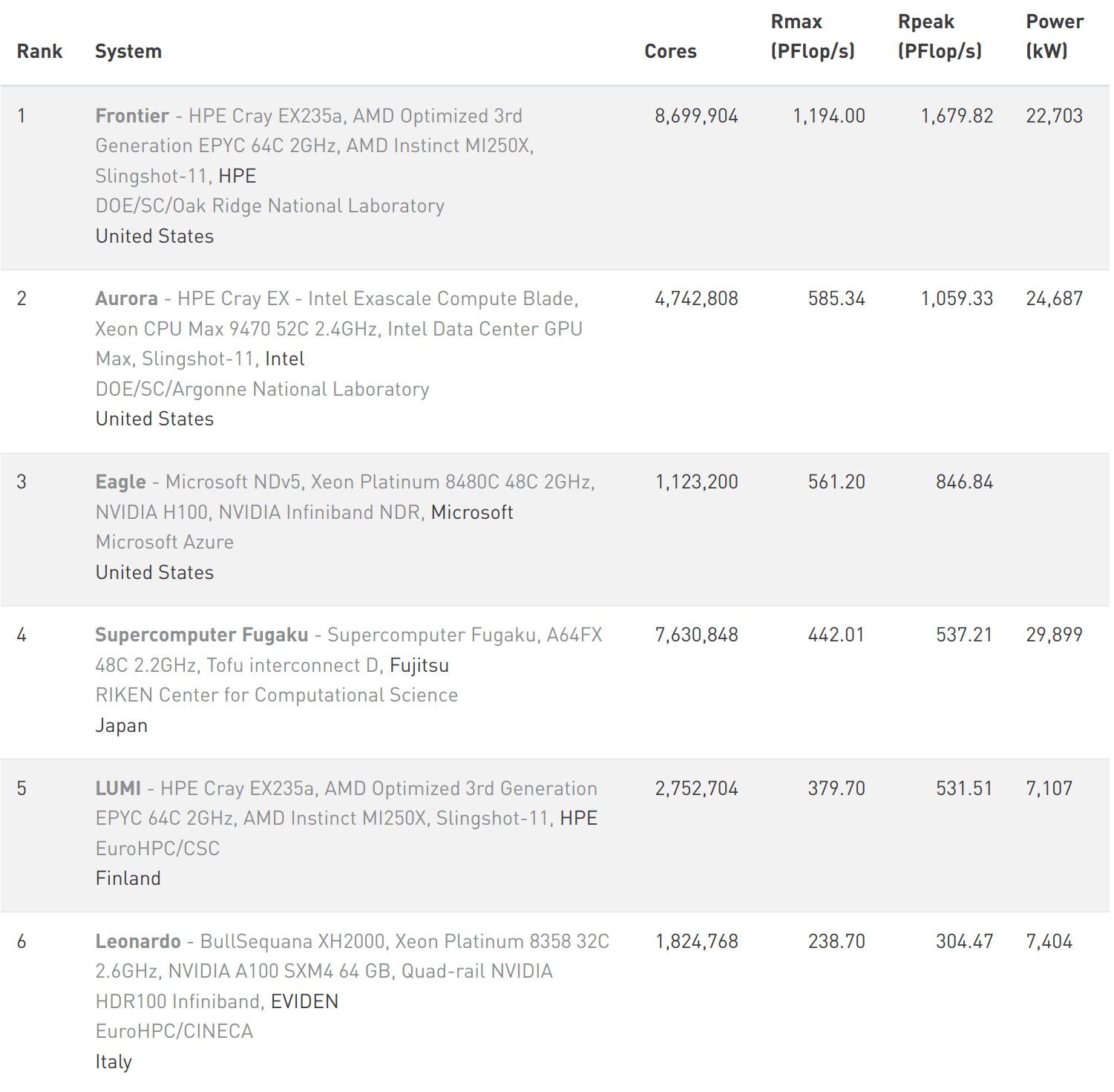
3.2 Examples


3.3 Green500
- List of the most energy efficient supercomputers in the world: Green500
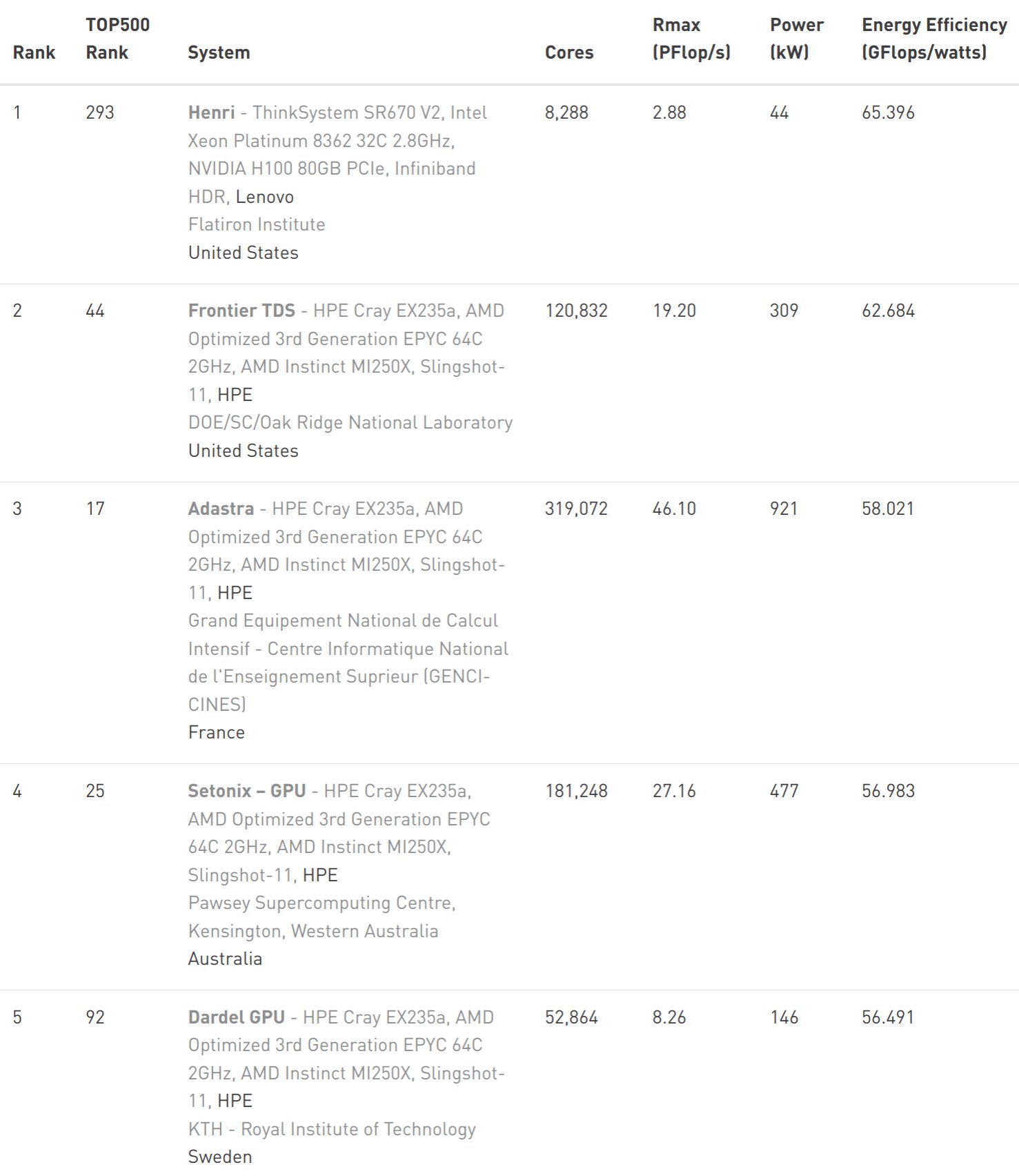
3.4 Quantum computing

3.5 Distributed vs cloud computing
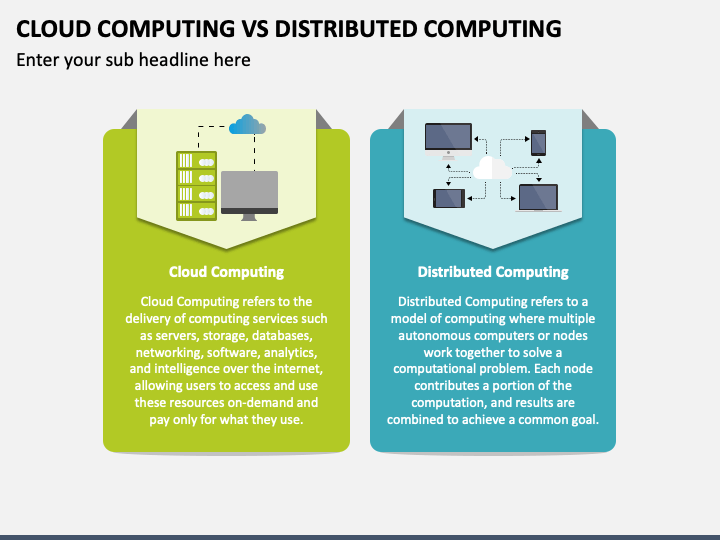
3.6 Access to a (super)computer
- Postdam Uni offers: HPC cluster for all members: Getting access
- Gauss center for supercomputing — Hawk, JUWELS, and SuperMUC-NG
- IT4I in Ostrava, CZ - Karolina, Barbora
- EuroHPC - LUMI, Leonardo, many others
- Many cluster offer free! training activities: EuroHPC, Gauss center — typicaly from very basic up to very advanced
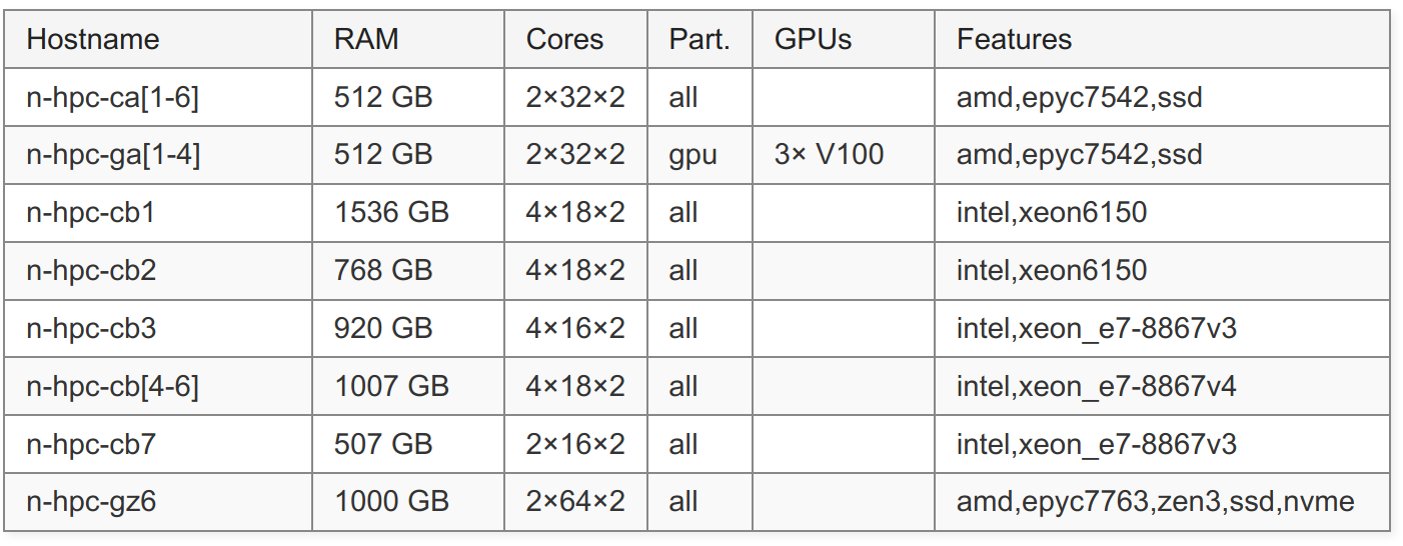
Node List of Uni Potsdam cluster
4.3 CPU - Central Processing Unit
- Basic and general-purpose processing unit of a computer
- Reads the instructions of a binary programs and executes them
- Advantage: can run various programs and types of loads, prepared be the control unit of a computer
- Disadvantage: Not many calculations can be done in parallel
- Execution speed approx. the clock speed (typically a few GHz)
- Two main techniques how to speed-up:
- Instruction level parallelism
- Task level parallelism
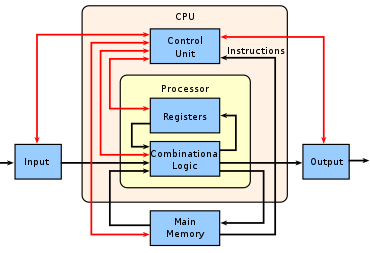
Scheme of a CPU Wiki.
4.4 Pipelines
- Every instruction of a program has several phases
- Pipeline: Load/Fetch instruction -> Decode -> (Load data) -> Execute -> Memory Access -> Write Back -> …
- This loop can be parallelized
- Different unit for each step
- E.g., when one instruction get decoded, next one can be already loaded.
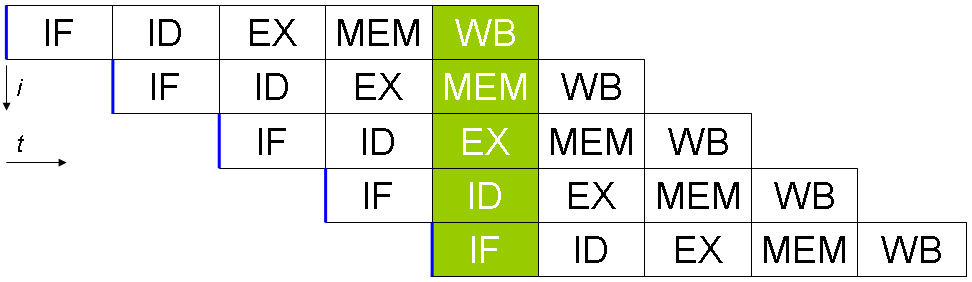
Pipeline
4.5 Superscalarity
- Each step in the pipeline can be also done in parallel
- Specific ones for floating point, integer, load, store operations
- Some pipeline items present more times
- Different execution times for integer: add (1 cycle); double: add (4 cycles), multiply (7), divide (23), sqrt(>23).
- Not every instruction takes the same place (a few to thousands of clock ticks)
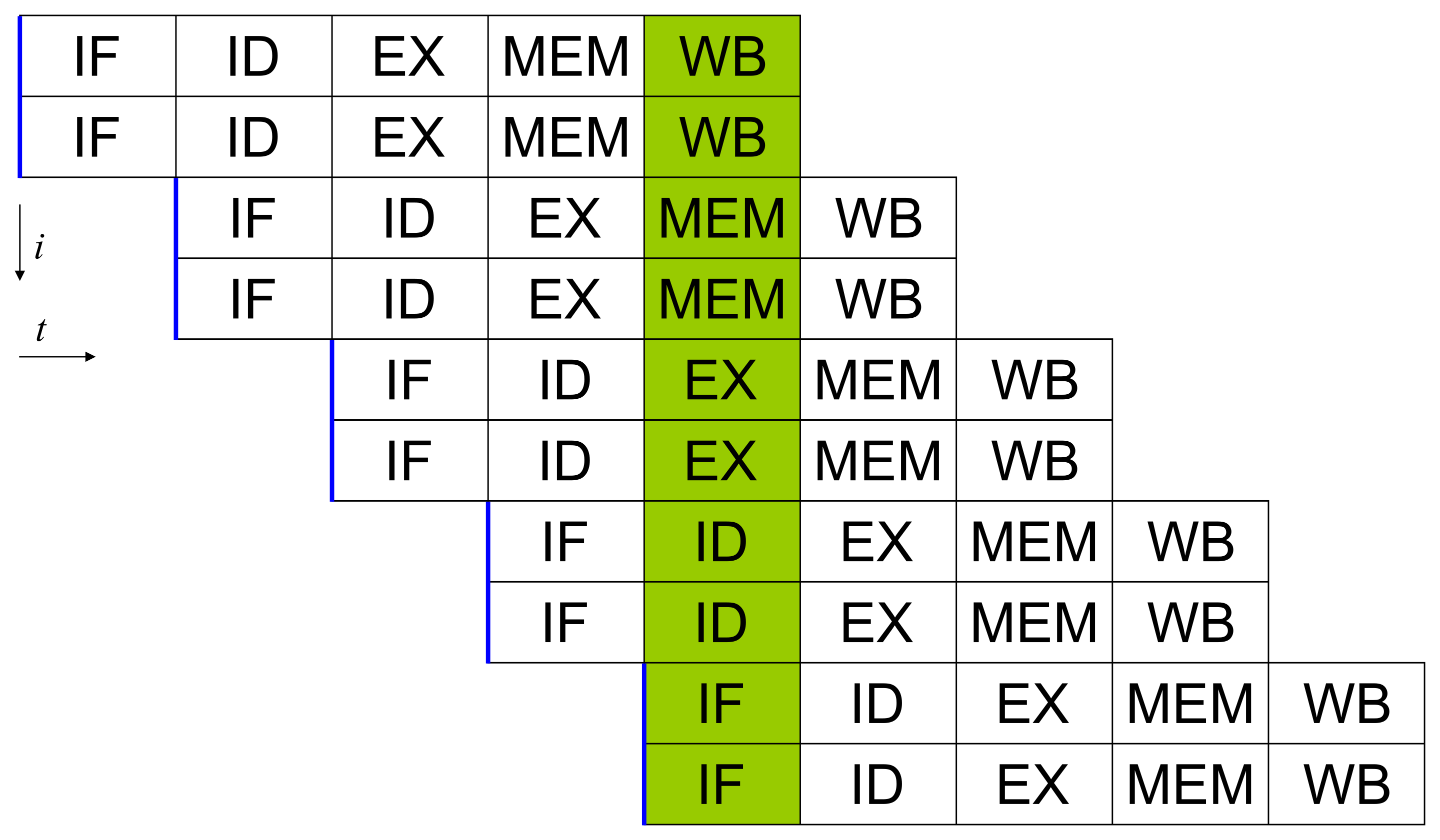
Superscalar pipeline
4.6 Vector Instructions
- To process even more data a time, each instruction can take more scalar values
- E.g., AVX512 instructions can take 8 Double scalars. The mathematical operation is simultaneous at all 8 numbers
- Advantage: increased performance up to 8 times
- Disadvantages:
- Large memory transports - large bandwidth required
- Not all processors support all types of vector operations
- The code (e.g., a loop) must be able to process data independently
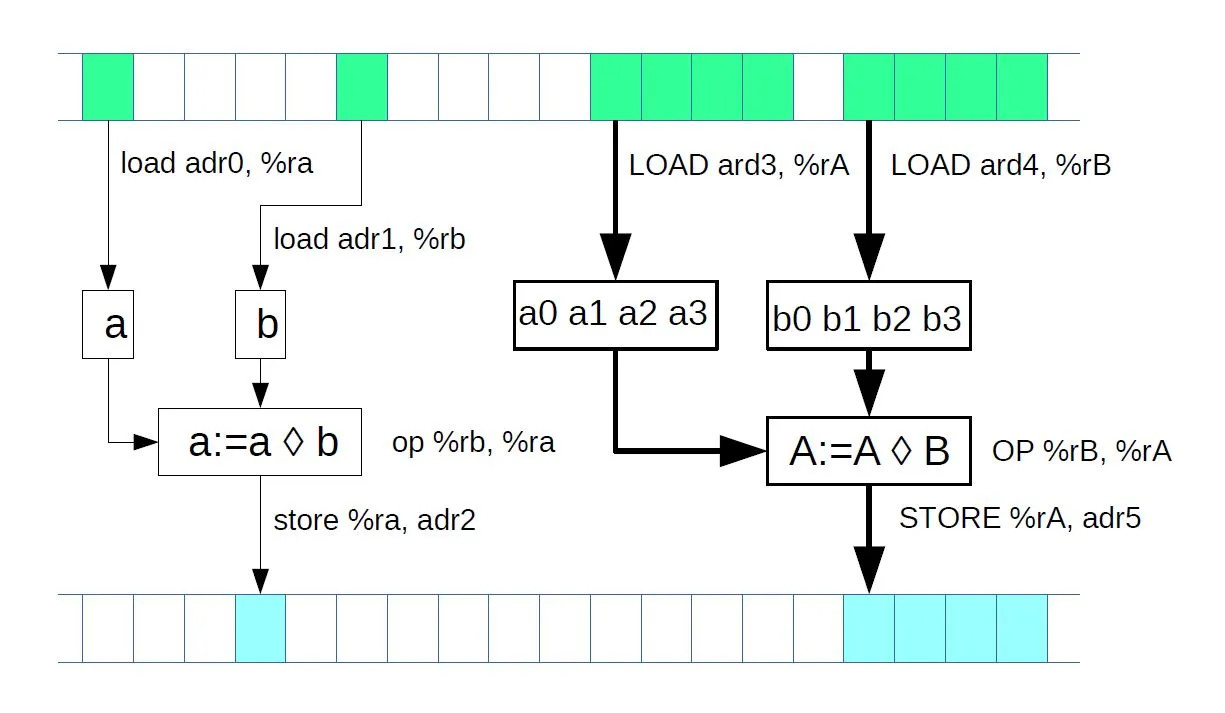
4.7 Threads — Hyperthreading
- To efficiently utilize all execution units, each core can run two or more independent threads
- The threads are indipendent programs, but they utilize the same execution units
- If the execution units not utilized, they would only wait and consume energy
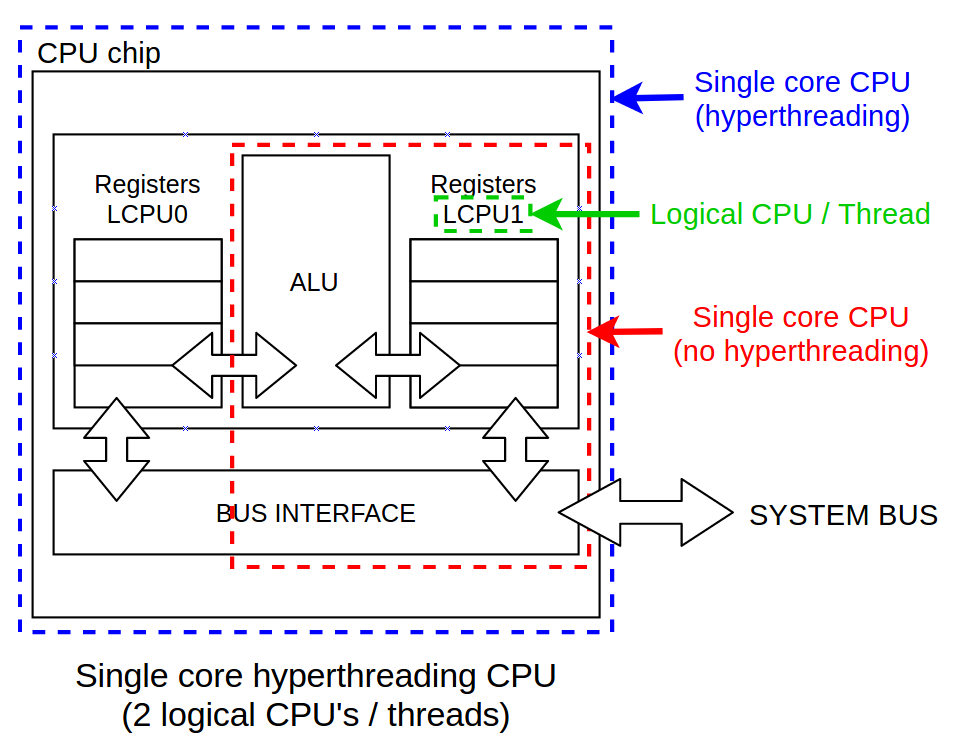
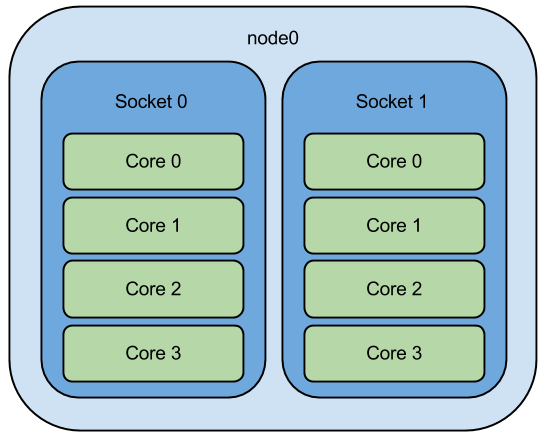
4.8 Cores
- Implementing more independent cores mean more programs can run in parallel
- However, if more programs solve the same issue, they have to communicate
- Communication between cores is relatively slow (~100 clock ticks)
- Also, the programs must be prepared (by programmer) to run more time and communicate to each other
- If not prepared, the parallel run at more cores is basically not possible
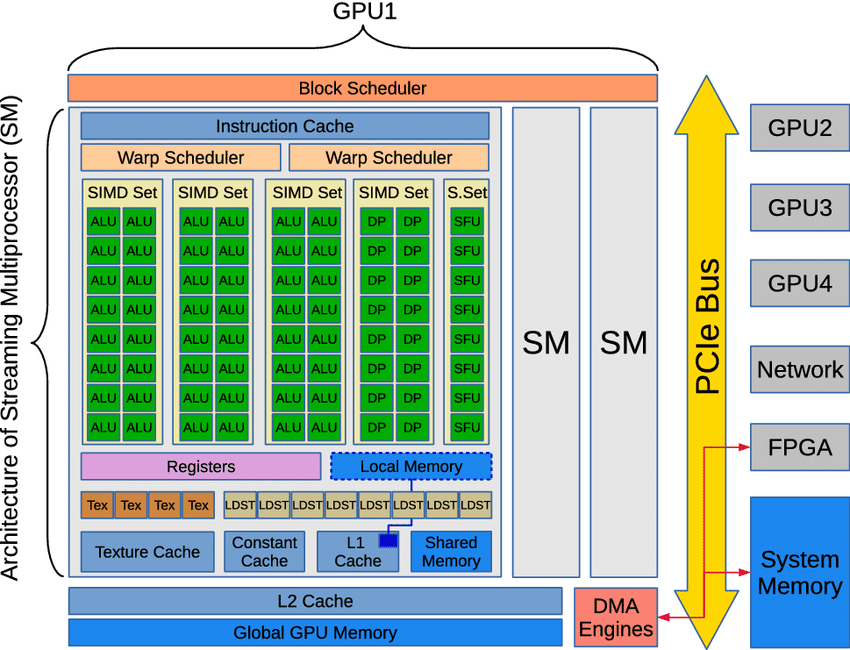
4.10 GPU - Graphical Processing Unit
- Originally developed for computer games
- Advantage: Relatively narrow-purpose unit to run as many simultaneous calculations as possible.
- Disadvantage: The programs must be prepared to take into account many execution units; if not, the program is running very inefficient way (and lots of power and money burned)
- Typical tick speed of 2 GHz
- Each multiprocessors many parallel execution units called stream processors
- Typical power: 16000 stream processors x 2 GHz = 32 TFlops (4 core CPU has 200-1000 GFlops)
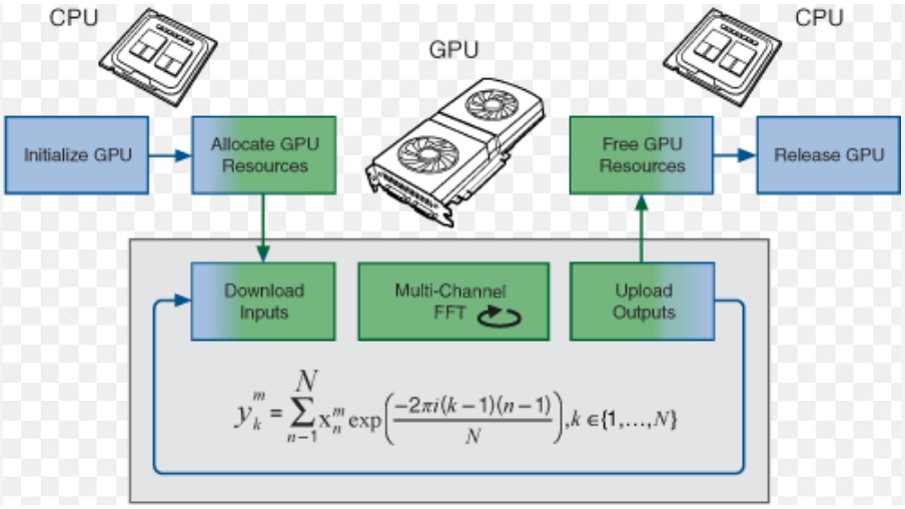
4.11 GPU acceleration — offloading
- Start our program on CPU
- Send the calculation to GPU
- Obtain the results from GPU
- Store/finish the simulation on CPU
4.12 Memory management
- Differences between CPU and GPU
- Scheme how data flow from RAM to L3, L2, L1 to L0 and execution unit
- Various times to transport the data \(\Rightarrow\) the best approach is to keep the programm to close to the core as possible
- Do not make dependent loops, if the program has to wait to something previous, it cannot proceed.
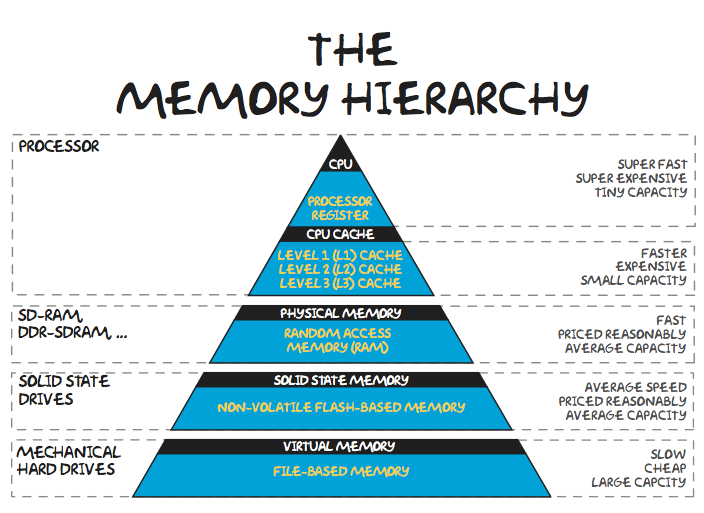
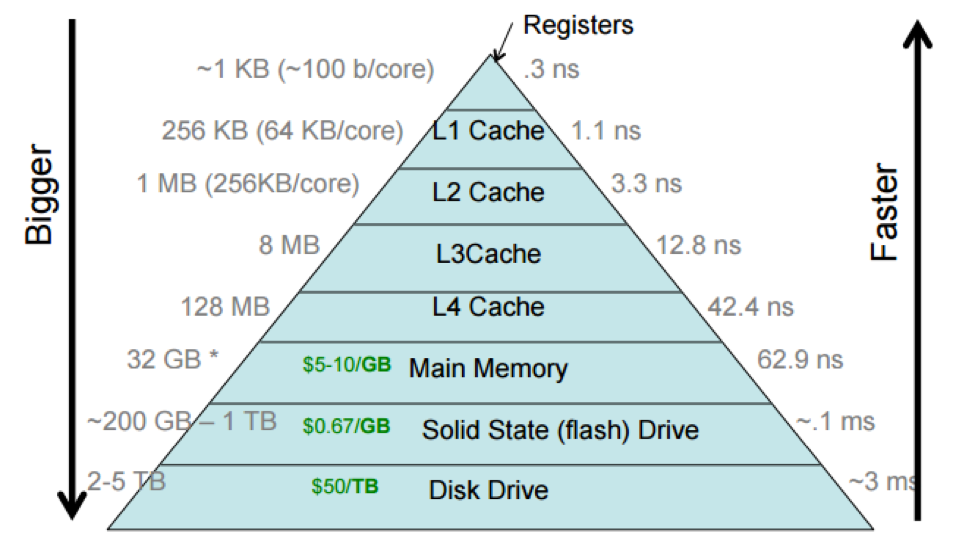
4.13 AMD Ryzen Die Scheme

5.1 Supercomputer scheme

Scheme of a MeluXina supercomputer (Luxembourg)